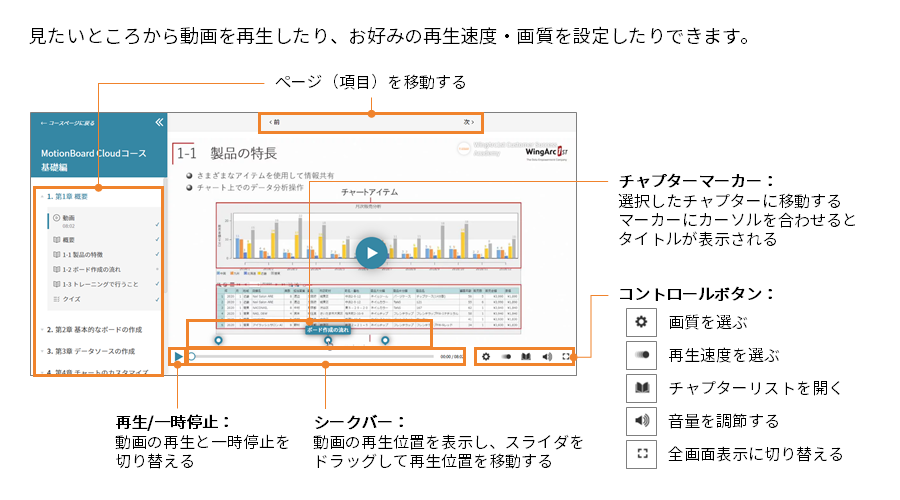
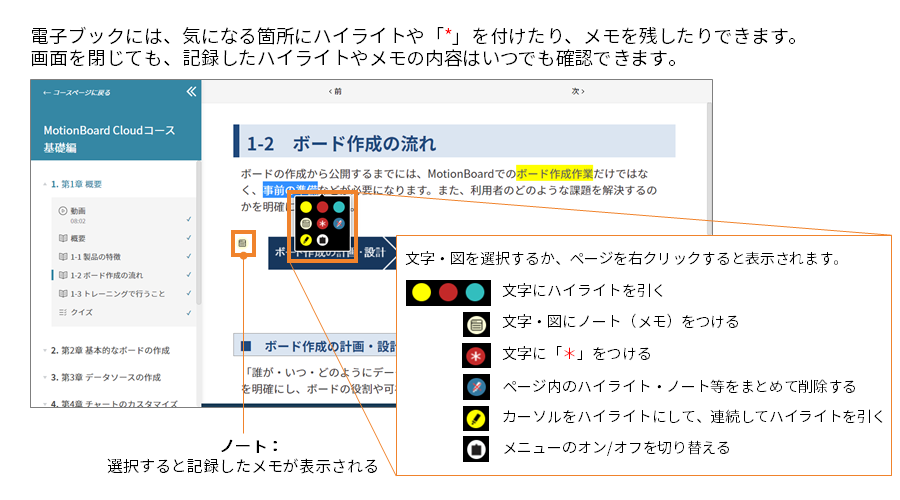
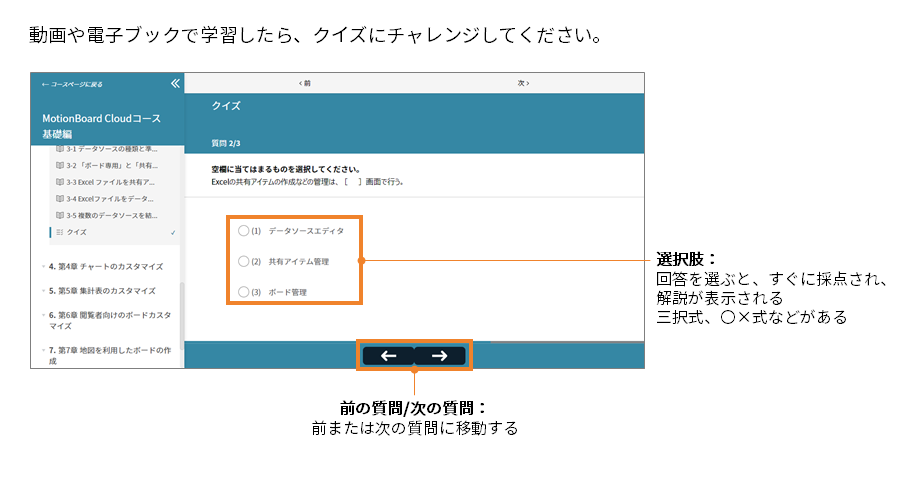
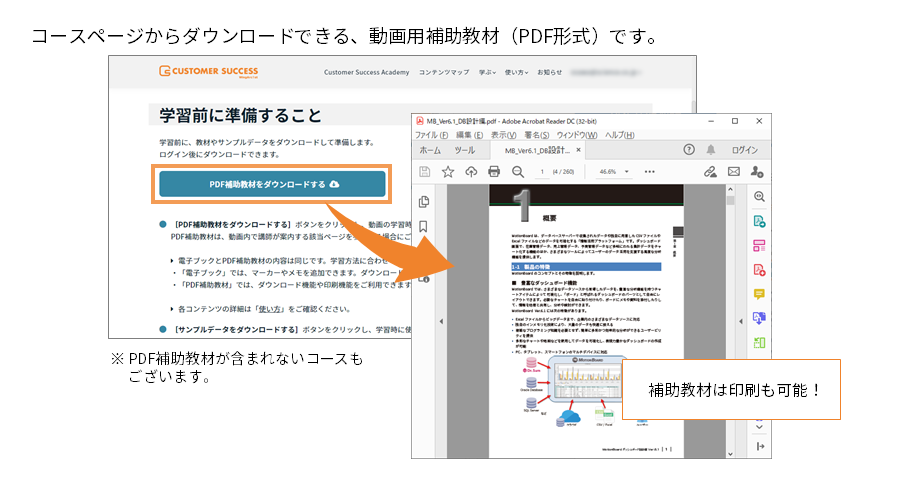
SQLを学んでみよう

1. データベースの準備
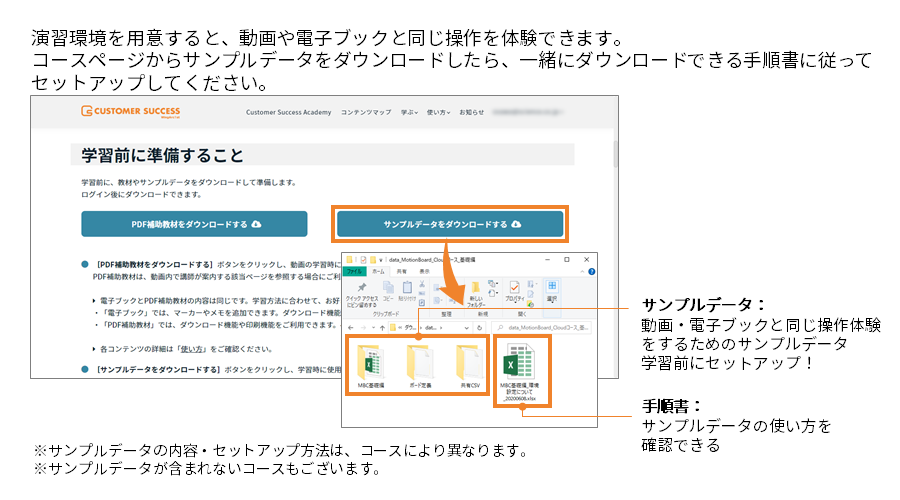
- まずはSQLを実行する環境を作りましょう。Dr.Sumサーバーにリモートデスクトップで接続できる場合はこちらのデータベースのダウンロードと設定を参照してデータベースをダウンロードし、あなたのDr.Sumの中で扱えるように設定をしてください。リモートデスクトップが使えない場合は、Web Consoleからデータベースを追加してみようを参照して、Web Consoleからデータベースを設定しましょう。
- Dr.SumはSQL実行ツールである、SQL Executorを使用します。SQL Executorの使い方について、こちらの記事を参照してください。
SQL(Structured Query Language)は、データベースを操作や制御するための言語のことだよ!
Data Definition Language
Data Manipulation Language
Data Control Language
テーブルの定義や削除を行う命令。
データ操作を行う基本命令。
データベースの権限管理に使用。
CREATE, ALTER, DROP, TRUNCATE
SELECT, UPDATE, INSERT, DELETE
GRANT, REVOKE
2. SQLってたとえばこんな感じ
まずはみんながよく見るSQLを解説するよ。
「あ、これは知ってる!」っていうクエリがあるか探してみてね!
鈴木
25
大阪
データの検索(SELECT)
SELECTはテーブルのデータを抽出します。
鈴木
25
大阪
データの挿入(INSERT)
INSERTはテーブルにデータを挿入します。
鈴木
佐藤
25
40
大阪
名古屋
データの更新(UPDATE)
UPDATEはテーブルの中のデータを更新します。
鈴木
佐藤
25
40
大阪
名古屋
データの削除(DELETE)
DELETEはテーブルの中のデータを削除します。
佐藤
40
名古屋
3. SELECT文にくわしくなろう
SELECT文ってどうやって書くの?
選択
どこから
条件
グループ化
グループの条件
並び替え
データベースから取得したい列(カラム)を指定します。
データを取得するテーブルを指定します。
特定の条件を満たすデータだけを取得します。
特定の列に基づいてデータをグループ化し、集計します。
グループ化した後のデータに対して条件を指定します。
取得したデータを特定の列に基づいて並び替えます。
SELECT 名前, 年齢
この例では、「名前」と「年齢」という列を取得します。
FROM 人
この例では、「人」というテーブルからデータを取得します。
WHERE 年齢 > 20
この例では、年齢が20歳より大きい人だけを取得します。
GROUP BY 性別
この例では、性別ごとにデータをグループ化します。
HAVING COUNT(*) > 1
この例では、2人以上のデータがあるグループだけを取得します。
ORDER BY 年齢 DESC
この例では、年齢のDESC(降順:大きい順)にデータを並び替えます。何も指定しないとASC(昇順:小さい順)になります。
このコンテンツをつくっている筆者も、SELECT文のすべての40%も知らないと思う。
だけどSQLを活かしてデータ活用をしているよ。
最初の一歩を踏み出すことが大事だね!
ためしてみよう
GROUP BYについてもう少し知ろう
GROUP BYの基本的な考え方
- グループ化:指定した列(カラム)ごとにデータを分けて、グループ化をします。
- 集計:各グループごとに計算を行います(例えば人数を数える、平均を出す など)。
簡単なビュー
GROUP BYの使い方
説明:
- SELECT 部署, AVG(年齢) AS 平均年齢:部署ごとに、年齢の平均を計算して表示します。ASはAVG(年齢)に別名を与えています。画面に表示するときに"平均年齢"と出した方がわかりやすくなるためです。
- FROM 部署従業員ビュー:データは「部署従業員ビュー」ビューから取得します。
- GROUP BY 部署名:部署ごとにデータをグループ化します。
結果:
平均値を四捨五入したいときはROUND関数を使い ROUND(AVG(年齢),1)とすることで、任意の桁位置で四捨五入ができます。
他の集計関数
例:COUNT(*)は各部署の人数を数えます。
例:SUM(年齢)は各部署の年齢の合計を計算します。
例:MAX(年齢)は各部署の最大年齢を取得します。
例:MIN(年齢)は各部署の最小年齢を取得します。
HAVING句
例えば、平均年齢が40歳以上の部署だけを表示したい場合、以下のようにSQL文を書きます。
まとめ
- GROUP BY句はデータをグループ化して、各グループごとに集計を行うために使います。
- COUNT、SUM、AVG、MAX、MINなどの集計関数と一緒に使うと便利です。
- HAVING句を使うと、グループ化後の条件を指定できます。
SELECT文を書いてみよう
やってみよう
SQL Executorを開いて、SELECT文を書いてみましょう。
主キーって何かわかるかな? Primary Key(PK)とも呼ばれるんだけど、そのテーブルの中で特定の一件を見つけるためにセットしておく情報だよ。従業員マスタならば同姓同名の人が存在するかも知れないけど、従業員IDを指定すれば、必ず特定の人にたどり着くよね!
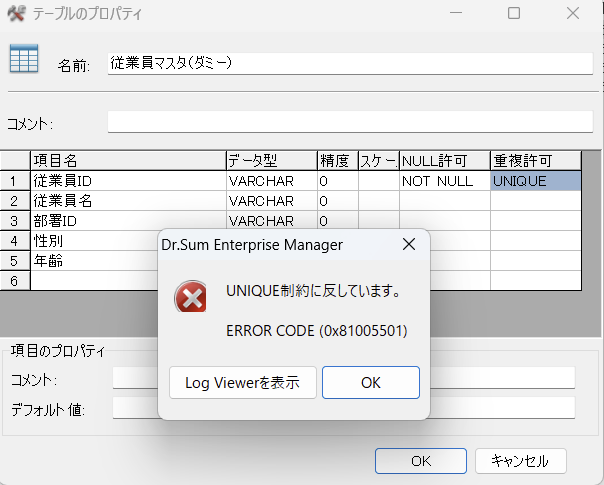
従業員IDでGROUP BYをして、従業員IDのCOUNTをすれば、そのID毎の件数がわかります。さらにHAVING句でCOUNTが1件より大きいものを表示させれば、従業員IDが2件以上(重複している)のデータが表示されることになります。
WHERE句についてもう少し知ろう
WHERE句の基本
説明:
テーブルからデータを取得するときにフィルタをかける役割を果たします。
「従業員」テーブルから、年齢が30歳以上の従業員を取得する場合:
ANDとOR
説明:
- AND:複数の条件すべてを満たす行を選択します。
- OR:複数の条件のいずれかを満たす行を選択します。
年齢が30歳以上で、かつ部署が「営業1部」の従業員を取得する場合
(両方の条件を満たす):
年齢が30歳以上、または部署が「営業1部」の従業員を取得する場合
(どちらかの条件を満たす):
IN
説明:
部署が「営業1部」または「営業2部」の従業員を取得する場合:
CASE
説明:
年齢が30歳以上の従業員には「シニア」、それ以外の従業員には「ジュニア」
と表示する場合:
まとめ
- WHERE句:条件に基づいて行を選択する
- AND:複数の条件すべてを満たす行を選択する。
- OR:複数の条件のいずれかを満たす行を選択する。
- IN:特定の値のリストの中にある行を選択する。
- CASE:条件に基づいて異なる値を返す。
4. 結合の種類
ここでは、主要な結合の種類と、特に左外部結合(LEFT JOIN)について詳しく説明します。
- 内部結合(INNER JOIN)
- 左外部結合(LEFT JOIN)
- 右外部結合(RIGHT JOIN)
- 完全外部結合(FULL OUTER JOIN)
1. 内部結合(INNER JOIN)
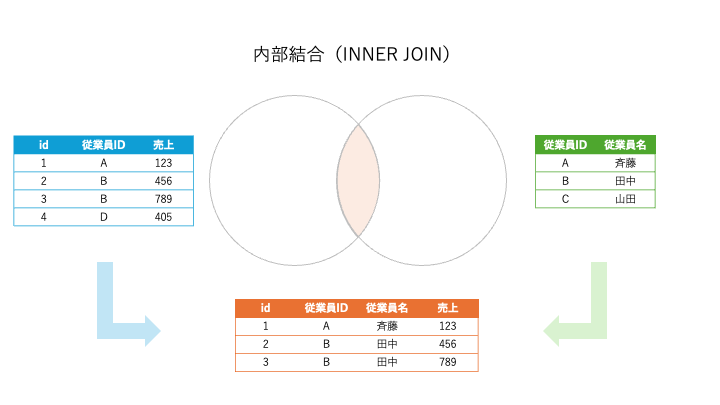
説明:
- 2つのテーブルの結合条件を満たす行だけを取得します。
- 共通するデータのみを取り出します。
従業員とその部署のデータを結合する場合:
結果:
2. 左外部結合(LEFT JOIN)
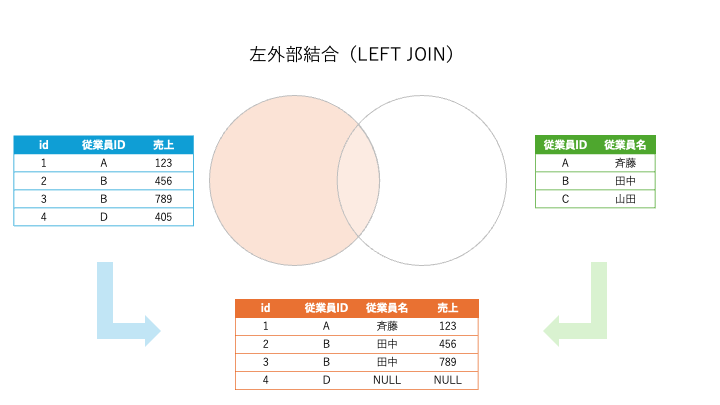
説明:
- 左のテーブルのすべての行と、右のテーブルの結合条件を満たす行を取得します。
- 結合条件を満たさない場合、右のテーブルの列はNULLになります。
- 左外部結合は、分析で欠損データを確認するのに非常に重要です。
すべての従業員のデータと、その従業員の部署が存在する場合は
そのデータを結合する場合:
結果:
左外部結合(LEFT JOIN)
テーブル例:
左外部結合クエリ:
結果:
詳細:
- 「田中」と「山田」は「営業」部署に所属しています。
- 「鈴木」は「開発」部署に所属しています。
- 「佐藤」はどの部署にも所属していませんが、左外部結合を使うことで従業員の情報をすべて取得できます(部署名はNULL)。
3. 右外部結合(RIGHT JOIN)
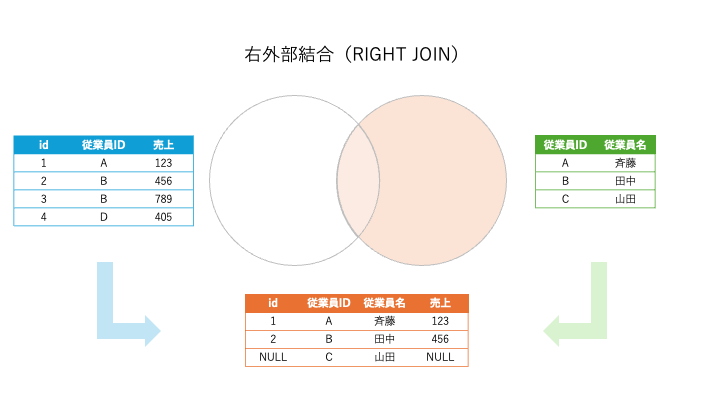
説明:
- 右のテーブルのすべての行と、左のテーブルの結合条件を満たす行を取得します。
- 結合条件を満たさない場合、左のテーブルの列はNULLになります。
すべての部署と、その部署に従業員が存在する場合は
そのデータを結合する場合:
結果:
4. 完全外部結合(FULL OUTER JOIN)
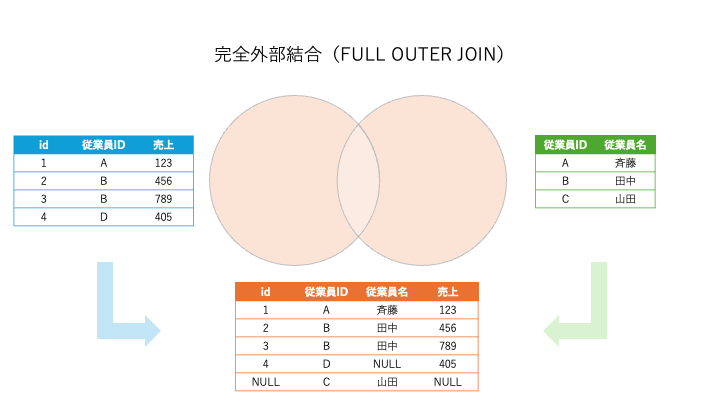
説明:
- 左右両方のテーブルのすべての行を取得し、結合条件を満たさない場合はNULLになります。
すべての従業員と部署のデータを結合する場合:
結果:
まとめ
- 内部結合(INNER JOIN):共通するデータだけを取得。
- 左外部結合(LEFT JOIN):左のテーブルのすべての行と、条件に一致する右のテーブルの行を取得。
- 右外部結合(RIGHT JOIN):右のテーブルのすべての行と、条件に一致する左のテーブルの行を取得。
- 完全外部結合(FULL OUTER JOIN):両方のテーブルのすべての行を取得。
5. 覚えておくと便利な関数
DECODE関数
基本的な使い方
書式:
説明:
- 式:評価する値。
- 検索値1, 検索値2, ...:比較する値。
- 変換値1, 変換値2, ...:対応する変換後の値。
- デフォルト値:式がどの検索値にも一致しなかった場合に返される値。
クエリ:
結果:
説明:
- DECODE(税フラグ, '1', '税あり', '2', '税なし', '不明'):税フラグが'1'の場合は「税あり」、'2'の場合は「税なし」、それ以外の場合は「不明」を返します。
NVL関数
基本的な使い方
書式:
説明:
- 式:NULLかもしれない値。
- 置き換える値:式がNULLの場合に代わりに使う値。
(NULLあり)
クエリ:
結果:
(NULLあり)
説明:
- NVL(部署ID(NULLあり), '未配属'):部署IDがNULLの場合は「未配属」と表示され、NULLでない場合はそのままの値が表示されます。
TO_CHAR関数、TO_DATE関数、TO_NUMERIC関数
1. TO_CHAR関数
説明:
- TO_CHAR関数は、数値や日付を文字列に変換します。
使い方:
1. 数値を文字列に変換
2. 日付を文字列に変換
2. TO_DATE関数
説明:
- TO_DATE関数は、文字列を日付に変換します。
使い方:
文字列を日付に変換
3. TO_NUMERIC関数
説明:
- TO_NUMERIC関数は、文字列を数値に変換します。
使い方:
文字列を数値に変換
具体例を使った説明
1:売上データ
(文字型)
クエリ:
まとめ
- TO_CHAR関数:数値や日付を文字列に変換します。
- TO_DATE関数:文字列を日付に変換します。
- TO_NUMERIC関数:文字列を数値に変換します。